Preface
We did receive a request from one of the customers to generate an enormous amount of load, to test their cloud platform, before making it GA.
The ‘Ask’
Requirement was to test if their platform is scalable, robust and stable enough
-
- to handle around a million agents connected with their platform.
- to handle around 50k http requests per second, during peak workloads.
- to capture MTTR, latency and http error-rate.
Solution & Approach
Existing solutions
- We tried existing performance benchmarking tools like JMeter, which worked well for initial small workloads, but as we scaled the number of requests dispatched per second, we ended up hitting the limitations of the threading model used internally by JMeter to support concurrent request dispatch.
- Threading model in JMeter was restricting the number of concurrent requests to the max number of threads allowed by OS as well as hardware capabilities of system(s), used as test-bed.
- In order to hit a large number of concurrent requests, we’ll need multiple machines with higher configurations, which would have eventually increased the budget.
- We had to support request-pipelining while connecting around a million agents with the platform.
- We had to instrument page load time for different pages in the UI, after generating different amounts of load.
Proposed solutions
- To cater to the requirements of dispatching large numbers of concurrent requests, with dynamic payloads, while limiting the hardware(test-bed) requirements, it was decided to develop a generic framework.
- Technologies used to build the framework:
- Python (Language)
- asyncio
- aiohttp
- Flask
- Pandas
- Initial POC yielded positive results and approval was obtained to develop a generic framework, which could support writing load simulations on any web platform.
Architecture
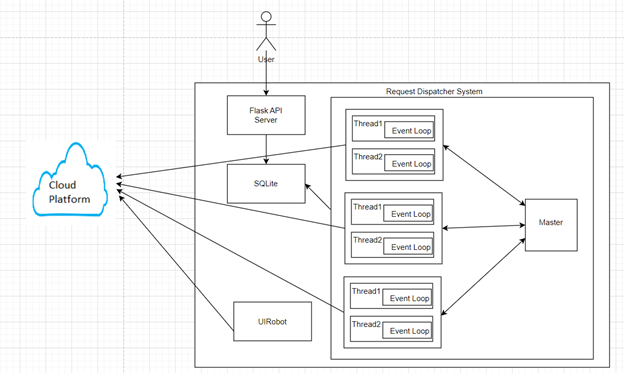
- Flask API server serves basic UI application, through which user can control, monitor and manage simulation.
- Simulation uses SQLite db as persistent storage to store information about simulation configuration, events occurring during simulation as well as response latency, http error rates, etc.
- Request Dispatcher Sub-system uses master-slave model to support distributed request dispatch
- Each node can dispatch over 10K requests on an average on a test-bed node.
- Master node controls the task distribution(batches) amongst worker nodes.
- Worker node dispatch requests in batches to the cloud platform and report status to master.
- Master node records events & metrics to SQLite.
- UIRobot is responsible for loading and accessing applications through UI, navigating different pages and capturing page load time and errors (if any).
- It uses selenium internally for interacting with the application UI.
Design Decisions
- A hybrid model was used in the request dispatcher sub-system.
- Hybrid model (Threading & asynio event loop) adopts the best from both the worlds of Threading and async programming model.
- Simulation will have a configuration number of threads.
- Each thread will have its own event loop, which will process request dispatching tasks independently.
- Simulation uses the Observer Design Pattern to aggregate and communicate task execution results asynchronously.
- SQLite as data-store
- SQLite offers almost all the rich querying capabilities that a SQL compliant relational database offers.
- Being lightweight, and having less system resources footprint, it outweighs the other choices (relations databases).
- For each simulation instance, there would be a different SQLite file being generated.
- Selenium for UI benchmarking
- To measure page-load time, under different volumes of load, selenium was used.
- Selenium has wide-support for different platforms and has a vibrant community.
- Moreover, availability of resources well-versed in selenium, made selenium default choice.
- Flask API server
- Other alternatives were Django and FastAPI.
- Using Django would have been overkill for relatively small application, as Django by default comes with a lot of sub-packages and features, not needed by the simulation.
- Flask being suitable for small size application, is a lightweight, pluggable and microframework.